Chacun a pu en faire le constat : les réseaux sociaux sont réellement devenus des plateformes incontournables sur internet. Ils facilitent la communication entre les individus, donnent l’occasion à leurs utilisateurs de découvrir et de se connecter à de nouvelles personnes et permettent aux entreprises d’y développer leur visibilité et leurs activités, gérer leur relation client, etc.
Dans ce cadre, notre startup iSoluce à choisi de développer depuis plusieurs années, et en partenariat avec le Laboratoire des Sciences de l’Information et des Systèmes de l’Université d’Aix – Marseille, des outils très performants permettant d’accroître votre audience et par conséquence, votre visibilité sur ces réseaux.
Ces outils sont littéralement dopés avec de l’intelligence artificielle (IA) ainsi que des données issues de millions d’interactions qu’ils ont déjà générées et qui ont été ensuite compilées, analysées, classées. (BigData)
Mais ces outils sont également TRES puissants et doivent être utilisés à bon escient, en respectant les usages d’internet et la confidentialité de ses utilisateurs.
C’est pourquoi nous avons réalisé de nombreux travaux de recherche afin de rendre l’utilisation de ces plateformes digitales plus intuitives tout en assurant en parallèle une véritable acculturation de ses utilisateurs.
Voici l’état des lieux de nos recherches
1. Les réseaux sociaux à lien faible*
2. Prédiction de Follow Back
3. La méthode d’iSoluce
4. Approche complémentaire
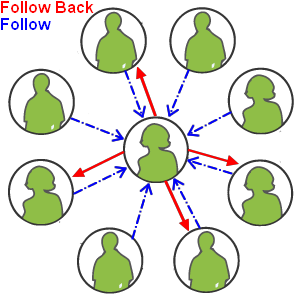
1. Les réseaux sociaux à lien faible
De nombreux réseaux sociaux gèrent les relations à sens unique (dans un seul sens) : on dit alors que ce sont des réseaux « à lien faible », par opposition aux réseaux à liens forts (ces derniers sont des réseaux permettant des connexions à double sens comme cela est pratiqué sur Facebook par exemple, ou sur Linkedin). Ces relations mettent en relief le concept d’« abonné ou abonnement » (follower & following sur Twitter) ou « éditeur-abonné » (publisher & subscriber). D’ailleurs, cette représentation est la plus adoptée dans les plates-formes de microblogging comme Twitter, par exemple.
Nous pouvons représenter ce type de relation dans une représentation à base de graphes comme un graphe orienté, ce qui signifie que l’utilisateur « a » peut suivre un autre utilisateur « b », alors que l’utilisateur « b » à l’inverse ne suit pas nécessairement l’utilisateur « a ».

Chacun d’entre vous connaît cette représentation sur ses propres comptes médias sociaux. C’est bon, à ce stade ? Vous me suivez ? 😊
2. Prédiction de Follow Back
Le projet ayant initié une collaboration entre la Faculté des sciences Saint Jérôme de l’Université d’Aix-Marseille et notre start-up iSoluce, s’articule essentiellement autour de la mise en place et le déploiement d’un système puissant et surtout proactif (c’est à dire un système qui anticipe les actions à réaliser selon les situations rencontrées)
Ce système permet donc de prévoir un Follow-Back (l’abonnement d’un contact en retour de notre propre abonnement) sur le réseau social Twitter.
Dans cette application que nous avons développée, nous avons fusionné des approches mathématiques et des algorithmes d’apprentissage automatique, pour aboutir ensuite à un indice de précision très important (0.835) et de pertinence plus élevée (comme mesure de performance d’un système d’information).
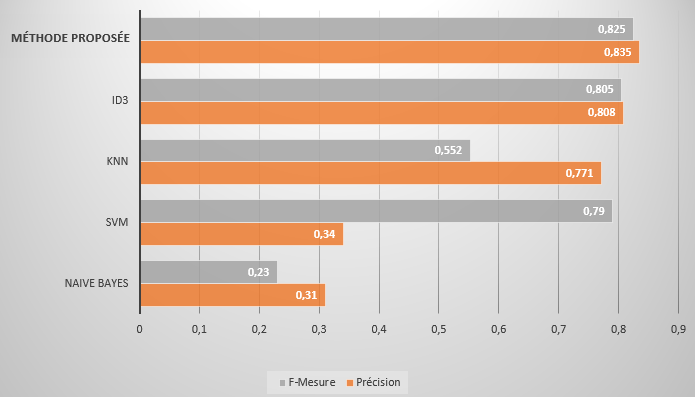
L’évaluation de la performance de la méthode que nous proposons a été réalisée à l’aide d’une compilation de données réelles (corpus) collectées sur nos propres comptes depuis janvier 2017.
Ces résultats démontrent que notre approche permet 83.5% de prédictions correctes parmi l’ensemble des données analysées (sur une base de 80.000 descriptions), ce qui renforce sa pertinence et sa fiabilité.

3. Notre méthode
Concrètement, notre technique consiste à créer « le modèle de l’utilisateur » en question, c’est-à-dire l’utilisateur sur lequel nous appliquerons notre méthode pour calculer le Follow Back potentiel.
Puis calculer la similarité avec la nouvelle personne demandeur de ce Follow-Back, en se basant sur un minimum de données (uniquement sur la description d’un compte d’utilisateur Twitter).
Les descriptions « bruitées » (parasitées) ou écrites sous forme d’un texte informel (description ayant une orthographe informelle contenant des abréviations par exemple, des acronymes ou des émoticônes …), sont également prises en compte et interprétées pour améliorer les résultats de recherche.
4. Approche complémentaire
Nous avons également réalisé une autre analyse sur les contenus (les descriptions des profils) pour construire le modèle de l’utilisateur en question, en appliquant l’allocation de Dirichlet latente qui est considéré comme l’un des algorithmes les plus performants, utilisés pour la modélisation des sujets.
(c’est un modèle* génératif probabiliste permettant d’expliquer des ensembles d’observations)
Sans vous immerger dans les méandres mathématiques articulées derrière ce modèle*, nous pouvons considérer que l’ensemble des descriptions collectées représente un mélange de sujets.
Nous imaginons ainsi que chaque ensemble peut contenir des mots de plusieurs sujets dans des proportions particulières.
Par exemple, dans un modèle à 2 sujets, nous pourrions évoquer :
“L’ensemble 1 représente 90% de sujets A et 10% de sujets B, tandis que l‘ensemble 2 représente 30% de sujets A et 70% de sujets B.”
Nous générons ainsi des familles thématiques, en quelque sorte !
D’où le fait que chaque sujet soit considéré comme un mélange de mots.
Voici un exemple concret :
Imaginons un modèle à 2 sujets d’actualité : un sujet sur la «politique» et un autre sur le «divertissement». (N’y voyez aucun rapprochement 😉 )
Les mots les plus courants du sujet politique pourraient être «président», «congrès» et «gouvernement», alors que le thème du divertissement pourrait se composer de mots tels que «film», «télévision» et «acteur».
Les mots peuvent être partagés entre les sujets ; Un mot comme «budget» pourrait apparaître dans les deux points égaux.
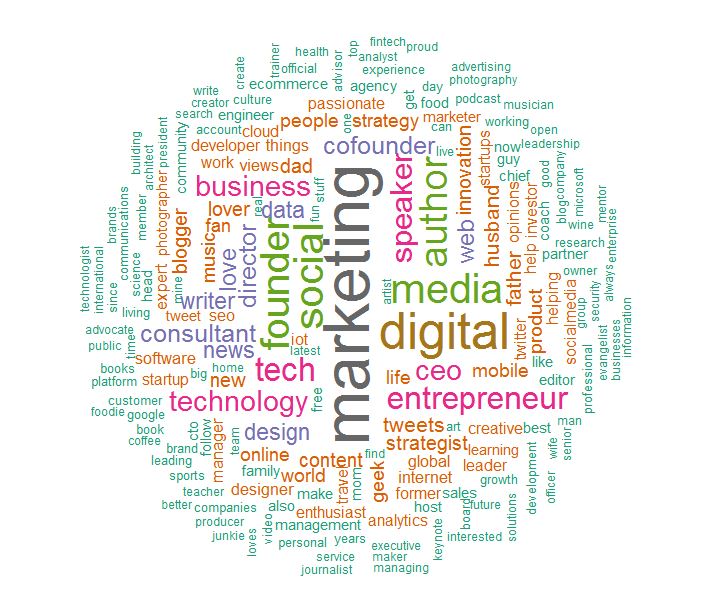
Suite à l’analyse réalisée sur nos comptes depuis début Janvier, les thématiques les plus figurantes et représentatives dans l’ensemble des « descriptions attractives » chez un utilisateur d’iSoluce, sont modélisées ci-dessous sous forme d’un nuage de mots.
La taille de ces mots varie également en fonction du nombre de personnes utilisant chacun d’eux dans sa description : plus un terme est utilisé, plus sa taille est grande !
Ce projet a ainsi permis aux utilisateurs d’iSoluce de bénéficier de sérieux atouts en découvrant à l’avance qui, parmi les personnes qu’ils ont décidé de suivre (leurs abonnements), serait ensuite susceptible de les suivre en retour.
Ce sujet est très intéressant dans le cadre de nos recherches et ouvre également de nombreux nouveaux champs d’action.
Les résultats enregistrés sur l’utilisation de notre technologie ont apporté une réelle valeur ajoutée à la recherche scientifique (science de l’information) mais également en termes de satisfaction client auprès des utilisateurs des applications de notre startup iSoluce.
Nos travaux ont ainsi fait l’objet d’une publication scientifique qui a été présentée lors d’une conférence internationale de rang A. Une très belle reconnaissance pour nous que nous sommes fiers de partager avec vous.

https://www.fuzzieee2017.org/sessionM10-4.html c’est l’article intitulé Leveraging Uncertainty Modeling for Suspicious Tweets Detection et Saad Mekkaoui est un collaborateur employé par iSoluce.
Actuellement, nous travaillons sur un nouveau modèle* scientifique qui permettra de matcher l’analyse des contenus avec l’analyse des profils. Cette recherche donnera ainsi l’opportunité aux utilisateurs de nos applications de bénéficier de contenus sur mesure et de découvrir des profils parfaitement en adéquation avec leurs propres centres d’intérêt. Et même dans les jeux en ligne populaires, vous pouvez en savoir plus.
Nous vous tiendrons informés sur l’évolution de nos travaux
Vous désirez en savoir plus sur nos applications ? Contactez-nous par mail à bienvenue@isoluce.net
*Un modèle est en quelque sorte une formule mathématique qui relie différentes données, de telle sorte que la relation qu’il décrit corresponde avec ce que l’on observe et ce que l’on mesure.
![]()
![]()